Cooperativismo y Desarrollo, enero-abril 2020; 8(1), 68-82
Indicador sintético mediante el análisis multivariado de la varianza aplicado al sector turístico
Composite indicator through multivariate analysis of variance applied to the tourism sector
Indicador sintético através da análise multivariada da variância aplicada ao sector do turismo
Reinier Fernández López1, José Alberto Vilalta Alonso2, Arely Quintero Silverio3, Rebeca María Chávez Gomis4
1Universidad de Pinar del Río "Hermanos Saíz Montes de Oca". Facultad de Ciencias
Técnicas. Departamento de Matemática. Pinar del Río. Cuba. ORCID:
https://orcid.org/0000-0003-1974-9209. Correo electrónico: rflopez@upr.edu.cu
2Universidad Tecnológica de La Habana (CUJAE). La Habana. Cuba. ORCID:
https://orcid.org/0000-0001-7505-8918. Correo electrónico: jvilalta@ind.cujae.edu.cu
3Universidad de Pinar del Río "Hermanos Saíz Montes de Oca". Facultad de Ciencias
Técnicas. Departamento de Matemática. Pinar del Río. Cuba. ORCID:
https://orcid.org/0000-0003-2951-8957. Correo electrónico: arelys@upr.edu.cu
4Universidad de Pinar del Río "Hermanos Saíz Montes de Oca". Facultad de Ciencias
Técnicas. Departamento de Matemática. Pinar del Río. Cuba. ORCID: https://orcid.org/0000-0001-6854-7596. Correo electrónico: rebeca.chavez@upr.edu.cu
Recibido: 9 de julio 2019.
Aprobado: 10 de enero 2020.
RESUMEN
En la actualidad, el proceso de medición de indicadores turísticos de Pinar del Río no proporciona
un indicador sintético que ofrezca un valor como medida de agregación del comportamiento de los
indicadores de turismo, al no emplearse en su obtención procedimientos que consideren varios
aspectos simultáneamente; lo anterior provoca que el proceso de toma de decisiones se vea afectado. En
este sentido, el presente trabajo consiste en elaborar un indicador sintético para las distintas cadenas
hoteleras mediante el empleo de técnicas de Análisis Multivariante de la Varianza, que permita la obtención de
una medida global para establecer un ranking que sustente el proceso de toma de decisiones en las
distintas cadenas hoteleras de Pinar del Río. Se utilizó, entre otros, los métodos estadístico-matemáticos, con el
fin de construir los indicadores sintéticos.
Palabras clave: bootstrap; indicador sintético; MANOVA; turismo
ABSTRACT
At present, the process of measuring tourist indicators in Pinar del Río does not provide a
composite indicator that offers a value as a measure of aggregation of the behavior of tourism indicators, since
no procedure that considers several aspects simultaneously is used to obtain it; This causes the
decision-making process to be affected. In this sense, the present work consists in developing a composite indicator for
the different hotel chains through the use of Multivariate Analysis of Variance techniques, which allows
obtaining a global measure to establish a ranking that supports the decision-making process in the different
hotel chains in Pinar del Río. Statistical-mathematical methods were used, among others, in order to
construct composite indicators.
Keywords: bootstrap; composite indicator; MANOVA; tourism
RESUMO
Atualmente, o processo de medição de indicadores turísticos em Pinar del Río não fornece um
indicador sintético que ofereça um valor como medida agregadora do comportamento dos indicadores turísticos,
uma vez que procedimentos que consideram vários aspectos simultaneamente não são utilizados para os
obter; isto faz com que o processo de tomada de decisão seja afetado. Neste sentido, o presente
trabalho consiste na elaboração de um indicador sintético para as diferentes cadeias hoteleiras através do uso
de técnicas de Análise de Variância Multivariada, que permite obter uma medida global para estabelecer
um ranking que suporte o processo de tomada de decisão nas diferentes cadeias hoteleiras de Pinar del
Río. Foram utilizados métodos matemáticos-estatísticos, entre outros, a fim de construir os
indicadores sintéticos.
Palavras-chave: bootstrap; indicador sintético; MANOVA; turismo
INTRODUCCIÓN
El análisis multivariante es una disciplina difícil de definir aunque, por lo general, agrupa diversas
técnicas estadísticas que, si bien muchas de ellas fueron ideadas por autores que se pueden denominar
clásicos, deben su auge y puesta en práctica a la difusión del software estadístico y a la creciente demanda que
de ellas exige el desarrollo de otras disciplinas (Montanero Fernández, 2008).
Es por ello que las investigaciones han utilizado, de manera creciente, en los últimos años, el análisis
de varianza con varias variables dependientes como técnica del análisis multivariante. Un acercamiento
típico ha sido realizar el análisis de varianza univariado para cada una de las variables dependientes. Sin
embargo, esto presenta como dificultad la inflación del error de tipo I (Camacho Rosales, 1990). El
análisis multivariado de varianzas (MANOVA) resuelve esta situación y dispone de técnicas globales
de significación (Lambda de Wilks, Traza de Hotteling-Lawley, Raíz máxima de Roy).
MANOVA es una generalización del análisis de la varianza univariante para el caso de más de una
variable dependiente (Ramos Álvarez, 2017). Se trata de contrastar la significación de uno o más factores
(variables independientes) para el conjunto de variables dependientes. Es un método estadístico para
explorar simultáneamente la relación entre varias variables categóricas y dos o más variables dependientes
medibles o métricas (Salgado Horta, 2006).
En el presente trabajo, se planteó como objetivo: elaborar un indicador sintético, mediante el empleo
de técnicas de Análisis Multivariante de la Varianza para las distintas cadenas hoteleras de Pinar del Río.
La aplicación del procedimiento MANOVA se hace difícil, si no se dispone de un programa
estadístico adecuado, por lo cual se utiliza en esta investigación el lenguaje estadístico R 3.5.3 y el software R
Studio 1.1.463, como soporte para el procesamiento de los datos.
MATERIALES Y MÉTODOS
Se utilizaron métodos empíricos de investigación, basados en la observación científica y el análisis
documental, lo que permitió caracterizar la situación actual de la medición de los indicadores turísticos en
Pinar del Río. La técnica de la entrevista para determinar las cadenas hoteleras que fueron incluidas en
la investigación y obtener información acerca de los indicadores turísticos. Entre los métodos
estadísticos matemáticos, se utilizaron técnicas de análisis multivariado como MANOVA. También se empleó
Bootstrap como herramienta, que permitió realizar transformaciones en las variables que no contemplaban
normalidad. Se emplearon los softwares R 3.5.3 y R Studio 1.1.463 para el procesamiento de los datos.
Paralelamente, se empleó el método de medición para la descripción y análisis del comportamiento de
los indicadores en cada una de las dimensiones, se determinó la validez de estos como representativos
del concepto que se pretende calcular.
También fueron utilizados métodos teóricos para reseñar el desarrollo de los actuales procesos de
gestión del turismo en Pinar del Río, a partir del empleo de indicadores. Como método lógico, la modelación,
para la construcción de las funciones que garantizan la confección del nuevo procedimiento de agregación.
Se emplearon operaciones de análisis y síntesis a través del estudio de los procedimientos de agregación
para la construcción de indicadores sintéticos.
Análisis multivariado de la varianza: MANOVA
Al igual que el análisis de la varianza (ANOVA), el análisis de varianza multivariante (MANOVA)
está diseñado para evaluar la importancia de las diferencias grupales. La única diferencia sustancial entre los
dos procedimientos es que MANOVA puede incluir varias variables dependientes, mientras que ANOVA
solo puede manejar una (Cuadras, 2014).
A menudo, estas variables dependientes no son más que diferentes medidas de un mismo atributo, pero
no siempre es así. Como mínimo, los variables dependientes deberían tener algún grado de linealidad
y compartir un significado conceptual común; deben tener sentido como un grupo de variables. La
lógica básica detrás de un MANOVA es esencialmente la misma que en un análisis de varianza univariante.
El MANOVA también opera con un conjunto de suposiciones, al igual que el ANOVA, las cuales
son (Avendaño Prieto et al., 2014):
1. Las observaciones dentro de cada muestra deben ser muestreadas al azar y deben
ser independientes entre sí.
2. Las observaciones de todas las variables dependientes deben seguir una distribución
normal multivariada en cada grupo.
3. Las matrices de covarianza de la población para las variables dependientes, en cada grupo,
deben ser iguales (esta suposición a menudo se conoce como la homogeneidad de la suposición de matrices
de covarianza o el supuesto de homocedasticidad).
4. Las relaciones entre todos los pares de las variables dependientes para cada celda, en la matriz
de datos, deben ser lineales.
Aclarando que la aleatoriedad debe garantizarse en el diseño, las muestras aleatorias las
debe predeterminar el investigador de antemano, antes de aplicar cualquier técnica.
Partiendo de las bases conceptuales, cuando se aplica la técnica multivariante MANOVA se contrasta
una sola hipótesis: que las medias de los g grupos son iguales en las p variables dependientes, que los g
vectores de medias de grupos (Llamados centroides) son iguales (Ramos Álvarez, 2017).
Metodología Bootstrap
La técnica Bootstrap, propuesta por Efron (1979), se basa en extraer muestras repetidamente, a partir
de un conjunto de datos de entrenamiento, ajustando el modelo de interés para cada muestra. Se trata
de métodos no paramétricos, que no requieren ninguna asunción sobre la distribución de la población
(Gil Martínez, 2018).
La idea básica es que, si se toma una muestra aleatoria x=(x1, x2, x3,…, xn) entonces la muestra puede
ser utilizada para obtener más muestras. El procedimiento es un remuestreo aleatorio (con reemplazo) de
la muestra original tal, que cada punto xi tiene igual e independiente oportunidad de ser seleccionado
como elemento de la nueva muestra bootstrap, o sea, P(x*= xi) = 1/n, i = 1,2,3,…, n
de una distribución con función de distribución F(x).
El proceso completo es repetición independiente de muestreo, hasta obtener un número grande de
muestras bootstrap. Múltiples estadísticos pueden calcularse para cada muestra bootstrap y, por lo tanto,
sus distribuciones pueden ser estimadas (Ramírez et al., 2013).
La función de distribución empírica F(x)n, es un estimador de F(x). Se puede probar que F(x)n es un estadístico suficiente de F(x); es decir, toda la información sobre F(x) contenida en la muestra está
también contenida en F(x)n. Aún más, F(x)n es en sí misma la función de distribución de una variable aleatoria,
a saber, la variable aleatoria que se distribuye de manera uniforme en el conjunto x=(x1, x2, x3,…, xn), por tanto, la función de distribución empírica F(x)n, es la función de distribución de X* (Gil Abreu, 2014).
Es conocido que la suma de n variables aleatorias, con distribución uniforme, se aproxima con rapidez a
la distribución normal (Solanas & Sierra, 1992). Por lo cual, en ausencia de normalidad, podemos utilizar
un algoritmo bootstrap para obtener B estimaciones de la media, basadas en B muestras obtenidas
por remuestreo sobre la muestra original (Vallejo et al., 2010).
La técnica bootstrap, en esta investigación, es aplicada para estimar medias, homogenizar la varianza
y lograr el supuesto de normalidad multivariada, tratando a la muestra como una especie de
universo estadístico. En este estudio en cuestión, se implementó el algoritmo propuesto por Efron (1979) el
cual sigue los siguientes pasos:
1. Dada la muestra de tamaño n, estime 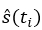 , donde en este caso, es la media a estimar.
, donde en este caso, es la media a estimar.
2. Genere B remuestras bootstrap de tamaño n mediante muestreo con reemplazamiento de la
muestra original, asignando a cada tiempo una probabilidad P(x*= xi) = 1/n, i = 1,2,3,…, n y calcular los correspondientes valores: 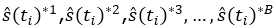 para
cada una de las B muestras bootstrap.
para
cada una de las B muestras bootstrap.
3. Estimar el error estándar del parámetro estimado , calculando la desviación estándar de las
B réplicas bootstrap. Así, obtenemos que el error estándar está dado por: 
Donde 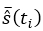 corresponde al promedio de la estimación de la función de confiabilidad evaluada en cada tiempo ti de la muestra bootstrap; el procedimiento se realiza con base en el tiempo de interés primer cuartil
(Ramírez Montoya et al., 2016).
corresponde al promedio de la estimación de la función de confiabilidad evaluada en cada tiempo ti de la muestra bootstrap; el procedimiento se realiza con base en el tiempo de interés primer cuartil
(Ramírez Montoya et al., 2016).
RESULTADOS Y DISCUSIÓN
La aplicación de entrevistas semiestructuradas con los actores del Ministerio del Turismo, en Pinar del
Río (Mintur) determinaron las cadenas hoteleras o entidades a tomar en consideración en esta investigación.
Las cadenas seleccionadas para establecer los indicadores sintéticos fueron Cadena Hotelera
Cubanacán, Cadena Hotelera Islazul y Campismo Popular. De estas entidades, se tomaron dos indicadores,
uno referente a la eficiencia: el costo por peso (costo/ingresos) y otro referente a la eficacia: los ingresos
por turista (ingresos/cantidad de turistas). Estos indicadores permitieron realizar el diagnóstico de las
entidades estudiadas, aplicando la herramienta MANOVA. Los datos tomados comprenden los valores entre
enero del año 2006 y diciembre del 2018.
A partir del análisis de los datos mediante los gráficos de caja (Fig. 1), se observa la existencia
de diferencias entre las entidades, siendo Campismo Popular la menos eficiente, pero la más eficaz,
mientras que Cubanacán mantiene bajos valores de costo por peso y de ingresos por turistas. Islazul
evidencia valores de costo por peso, similares a Cubanacán, aunque la supera en los ingresos/turista mostrando
buena gestión en cuanto a eficiencia y eficacia.
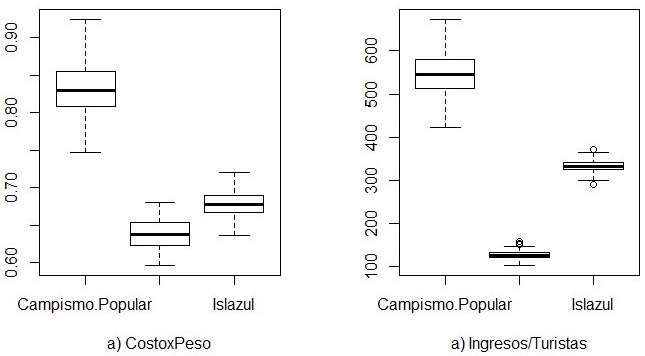
Fig. 1 - Gráficos de cajas para costo por peso e ingresos promedio por turista por cada entidad turística
Fuente: R, versión 3.5.3
Los coeficientes de correlación de Pearson entre las variables dependientes (costo por peso e ingreso
por turista), analizadas en la institución de Campismo y las Cadenas Hoteleras Cubanacán e Islazul fueron de
-0.20436, -0.13801 y -0.29271 respectivamente, no mostrando relación lineal significativa estas
variables (prueba de significación con valor p>0.05). Este resultado, sin embargo, es contrario a lo que
cabría esperar como resultado de una buena gestión turística. En la figura 2, se puede observar lo
antes mencionado.

Fig. 2 - Gráficas de dispersión costo por peso contra ingreso promedio por turista por cada
entidad turística
Fuente: R, versión 3.5.3
Al realizar una prueba de significación para las correlaciones entre las variables dependientes, esta
tiene como resultado un valor de probabilidad igual a 0.026 para el total de los datos, rechazándose la
hipótesis de no correlación.
En la figura 3, se muestra el gráfico de dispersión con elipses, por tipo de entidad, el cual
brinda información sobre la existencia de problemas con el supuesto de matrices de covarianza constantes
dentro del grupo (Fox et al., 2013).
Las elipses formadas por los datos de cada entidad contienen diferencias notables en cuanto a
forma, debido al no cumplimiento del supuesto de igualdad de varianzas. Por lo general, esto se debe a la
ausencia de normalidad.

Fig. 3 - Gráficas de dispersión con elipses por entidad turística
Fuente: R, versión 3.5.3
Sin el empleo de pruebas de hipótesis referentes a la normalidad de los datos, se puede comprobar en
la figura 4 que este supuesto se viola. Como se visualiza en la propia figura, el conjunto de
variables dependientes no mantiene la normalidad; por definición de la normalidad invariante no se mantendrá
la normalidad multivariada del conjunto de variables dependientes, con lo cual, el modelo MANOVA
perdería validez (Ordaz Sanz et al., 2011).

Fig. 4 - Gráfico de dispersión con histograma y con coeficiente de correlación
Fuente: R, versión 3.5.3
Comprobando las sospechas de la ausencia de normalidad multivariada, se procede a realizar las
pruebas de normalidad múltiple, propuestas por Mardia (1970), las cuales se determinan mediante R,
arrojando valores de probabilidad, inferiores al nivel de significación (p<0.05), rechazando la hipótesis
nula (normalidad multivariada). En este momento, se hace necesario encontrar una transformación
aceptable como respuesta a este problema. Existe un método que permite obtener, de una forma rápida,
una transformación que proporciona ciertos beneficios.
Bootstrap, el cual está basado en la idea de tratar a la muestra como una especie de "universo
estadístico", muestreando repetidamente y utilizando las muestras para estimar medias, varianzas, sesgos e intervalos
de confianza para los parámetros de interés (Ramírez Montoya et al., 2016).
La aplicación de la técnica de Bootstrap permitió el cumplimiento del supuesto de normalidad de los
datos. A continuación, se procede a realizar un MANOVA más adecuado, con el objetivo de comprobar si
existen diferencias en el comportamiento de los indicadores de eficiencia y eficacia en las distintas
entidades turísticas. R facilitó la aplicación del MANOVA con sus respectivas pruebas de significación (Pillai,
Wilks, Hotelling y Roy). Según estas pruebas de significación (p<0.05), se puede concluir que existen
diferencias en los parámetros: eficiencia y eficacia entre las distintas entidades.
Ahora se procede a analizar cada variable dependiente por separado, o sea, realizar un análisis de
la varianza de un factor para verificar en cuál o cuáles variables dependientes hay diferencias entre las
distintas entidades.
En la salida de R, para el análisis de los costos por peso, se comprobó la existencia de
diferencias significativas entre las entidades (p<0.05), con un coeficiente de determinación ajustado de 0.9856, el
cual se puede traducir como el porciento de variabilidad que es explicada por los factores.
Procediendo a analizar los residuos de la prueba que se muestran en la figura 5, se puede comprobar
que los supuestos básicos se cumplen, exceptuando el supuesto de igualdad de varianza (Residual vs.
Fitted values). Esto se debe a la influencia en cuanto a variabilidad que le impregna la entidad Campismo.

Fig. 5 - Gráficos de los residuos para el ANOVA del costo por peso
Fuente: R, versión 3.5.3
También, en salida de R, se comprueba que el valor de probabilidad es menor que el nivel de
significación, lo que se interpreta como la existencia de diferencias estadísticamente significativas entre estas entidades,
en cuanto al comportamiento de la variable dependiente ingresos por turistas, con un coeficiente
de determinación ajustado de 0.9094.
Analizando los residuos del modelo (Fig. 6), se puede comprobar que no existe homogeneidad de
varianzas (Residual vs. Fitted values), lo cual es debido a las diferencias que impone Campismo Popular en cuanto
a sus propias características, respecto al resto de las demás entidades.

Fig. 6 - Gráficos de los residuos para el ANOVA de los ingresos promedio por turista
Fuente: R, versión 3.5.3
Repitiendo el procedimiento para el análisis de la varianza, pero sin incluir Campismo Popular, se logra
el cumplimiento del supuesto de homogeneidad de varianzas para las entidades Islazul y
Cubanacán, corroborándose de este modo lo explicado anteriormente. A partir de aquí, se pueden obtener
resultados más limpios al aplicar la herramienta del análisis multivariado de datos. En la figura 7, se muestra
el cumplimiento de este supuesto.

Fig. 7 - Gráfico de los residuos para realizar el análisis del supuesto de igualdad de varianza
Fuente: R, versión 3.5.3
Al efectuar el ANOVA, sin incluir la entidad de Campismo Popular, los resultados arrojados por el
software para las variables costo por peso e ingresos por turistas, muestran diferencias significativas entre
las entidades involucradas para ambos indicadores (p<0.01), con coeficientes de determinación de 0,53
y 0,985 respectivamente.
Para la conformación del indicador sintético (Tabla 1), fue necesario asignar a cada subindicador el
mismo peso que a los demás; en este caso, los coeficientes de determinación R2 agregando la
información mediante una suma (Torres Delgado & López Palomeque, 2017). La ponderación y agregación
suele hacerse en niveles sucesivos, de manera que previamente se ponderan y agregan una serie de variables
para construir los subindicadores relativos a una determinada dimensión y, posteriormente, se agregan estos
para construir el indicador sintético (Nardo et al., 2005). Así, el indicador para una unidad i se define como 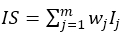 donde wj es el peso asignado al indicador j.
donde wj es el peso asignado al indicador j.
Tabla 1 - Conformación de los indicadores de eficiencia y eficacia
Entidad |
Costo por peso
R2 |
Ingreso por turista
R2 |
Costo por peso
1-CV |
Ingreso por turista
1-CV |
Suma ponderada |
Ranking |
Cubanacán |
0.5313 |
0.985 |
0.6012 |
0.0794 |
0.3976 |
2 |
Campismo |
0.9856 |
0.9094 |
0.3353 |
0.0208 |
0.3493 |
3 |
Islazul |
0.5313 |
0.985 |
0.6676 |
0.3734 |
0.7224 |
1 |
Fuente: Elaboración propia
Como indicador normalizado, se utilizó el complemento del coeficiente de variación (CV) el cual mide
el grado de homogeneidad de los valores de la variable. El CV es una medida del grado de
heterogeneidad; se utiliza fundamentalmente para comparar períodos o etapas y permite hacer comparaciones
entre conjuntos de datos heterogéneos.
Una vez determinados los pesos wj y el indicador normalizado, los valores del indicador sintético
se obtienen mediante una suma ponderada de los valores normalizados de los indicadores del sistema
(Parada et al., 2015).
En la tabla 1, se aprecia que la cadena hotelera con mejores resultados es Islazul, mientras que
Campismo Popular evidencia una situación menos adecuada en cuanto eficiencia y eficacia, la cual está más alejada,
en cuanto a puntuación, del resto de las entidades, sobre todo por los problemas de eficiencia que presenta.
En el trabajo, queda demostrada la importancia del análisis multivariado de la varianza en el diagnóstico
de la eficiencia y eficacia de la actividad turística, a partir del cálculo de un índice sintético.
Su aplicación en la provincia Pinar del Río, Cuba, permitió determinar las puntuaciones para construir
un ranking entre las entidades turísticas, convirtiéndose en una herramienta para el análisis estratégico
del sector.
REFERENCIAS BIBLIOGRÁFICAS
Avendaño Prieto, B. L., Avendaño Prieto, G., Cruz, W., & Cárdenas Avendaño, A. (2014). Guía
de referencia para investigadores no expertos en el uso de estadística multivariada. Diversitas: Perspectivas
en Psicología, 10(1), 13-27. http://www.scielo.org.co/scielo.php?script=sci_abstract&pid=S1794-99982014000100002
Camacho Rosales, J. (1990). Interpretación del MANOVA: Análisis de la importancia de las
variables dependientes. Investigaciones, 10.
Cuadras, C. M. (2014). Nuevos métodos de análisis multivariante. CMC Editions.
Efron, B. (1979). Bootstrap methods: Another look at jackknife. The Annals of Statistics, 7(1), 1-26.
https://projecteuclid.org/download/pdf_1/euclid.aos/1176344552
Fox, J., Friendly, M., & Weisberg, S. (2013). Hypothesis Tests for Multivariate Linear Models Using
the car Package. The R Journal, 5(1), 39-52. https://doi.org/10.32614/RJ-2013-004
Gil Abreu, S. N. (2014). Bootstrap en poblaciones finitas [Máster Oficial en Estadística
Aplicada]. Universidad de Granada.
Gil Martínez, C. (2018). Métodos de remuestreo y validación de modelos: Validación cruzada y bootstrap.
Mardia, K. V. (1970). Measures of multivariate skewness and kurtosis with applications.
Biometrika, 57(3), 519-530. https://doi.org/10.2307/2334770
Montanero Fernández, J. (2008). Análisis Multivariante. Universidad de Extremadura.
Nardo, M., Saisana, M., Saltelli, A., Tarantola, S., Hoffman, A., & Giovannini, E. (2005). Handbook
on Constructing Composite Indicators: Methodology and User Guide. OECD.
Ordaz Sanz, J. A., Melgar Hiraldo, M. del C., & Rubio Castaño, C. M. (2011). Métodos estadísticos
y econométricos en la empresa y para finanzas. Universidad Pablo de Olavide.
https://www.upo.es/export/portal/com/bin/portal/upo/profesores/jaordsan/profesor/1381243330001_metodos_estadisticos_y_econometricos_en_la_empresa_y_para_finanzas.pdf
Parada, S., Fiallo, J., & Blasco Blasco, O. (2015). Construcción de indicadores sintéticos basados
en juicio experto: Aplicación a una medida integral de la excelencia académica. Revista Electrónica
de Comunicaciones y Trabajos de ASEPUMA, 16(1), 51-67.
https://dialnet.unirioja.es/servlet/articulo?codigo=5601445
Ramírez, I. C., Barrera, C. J., & Correa, J. C. (2013). Efecto del tamaño de muestra y el número
de réplicas bootstrap. Ingeniería y Competitividad, 15(1), 93-101.
Ramírez Montoya, J., Osuna Vergara, I., Rojas Mora, J., & Guerrero Gómez, S. (2016).
Remuestreo Bootstrap y Jackknife en confiabilidad: Caso Exponencial y Weibull. Revista Facultad de
Ingeniería, 25(41), 55-62. http://www.scielo.org.co/scielo.php?script=sci_arttext&pid=S0121-11292016000100006
Ramos Álvarez, M. M. (2017). Curso de análisis de investigaciones con programas
informáticos. Universidad de Jaén.
Salgado Horta, D. (2006). Métodos estadísticos multivariados.
Solanas, A., & Sierra, V. (1992). Bootstrap: Fundamentos e introducción a sus aplicaciones. Anuario
de Psicología, 55, 143-154.
Torres Delgado, A., & López Palomeque, F. (2017). The ISOST index: A tool for studying
sustainable tourism. Journal of Destination Marketing & Management, 8, 281-289.
https://doi.org/10.1016/j.jdmm.2017.05.005
Vallejo, G., Fernández, M. P., Tuero, E., & Livacic Rojas, P. E. (2010). Análisis de medidas
repetidas usando métodos de remuestreo. Anales de Psicología, 26(2), 400-409.
http://www.redalyc.org/articulo.oa?id=16713079025
Conflicto de intereses:
Los autores declaran no tener conflictos de intereses.
Contribución de los autores:
Los autores han participado en la redacción del trabajo y análisis de los documentos.

Esta obra está bajo una licencia Creative Commons Reconocimiento-NoComercial 4.0 Internacional
Copyright (c) Reinier Fernández López, José Alberto Vilalta Alonso, Arely Quintero Silverio, Rebeca María Chávez Gomis